
Reference graphs
As described in the data section, the evaluation will be based on the comparison of the similarity graphs provided by participants with the reference graph, for the test partition.
The quality of a similarity graph will be computed the cosine similarity function given by
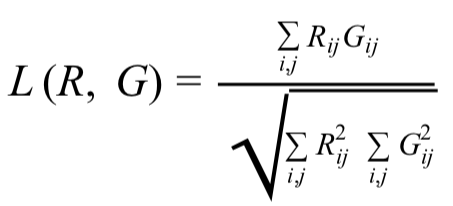
where R is the matrix of the reference graph and G is the similarity matrix computed by the participants
In response to this call, participants will have to submit:
- A description of the NLP pipelines.
- A description of the similarity function based on the intermediate representation of the items
- The estimated semantic similarity between each pair of documents in the test partition.
Additionally, the team ranked 1st will be requested to provide the intermediate representation of documents after the NLP pipelines

